![[C] 3. 좀 더 다양한 종류의 변수를 선언해봅시다. <다양한 자료형>](https://img1.daumcdn.net/thumb/R750x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdn%2FOtoG8%2FbtrFKmBInTZ%2FYfmRh7yTTfvdDSOJWRYQE0%2Fimg.png)

변수는 자료형과 이름, 초기값을 알리는 것으로 선언된다.
이것을 기억하시죠?
이번 글은 자료형이라는 것을 깊이 파헤쳐 보는 글입니다.
내용이 많아보이지만 나중에 돌아보면 다 별 거 아닌 것들입니다.
덜컥 겁을 먹고 공부가 하기 싫어질 수도 있지만,
그런 과정까지 기억에 남아서 나중에는 "이 쉬운 걸 힘들어 했었네." 하게 될 겁니다.
그럼 시작합시다.

자료형은 Data Type, 즉 저장하려는 데이터의 종류입니다.
자료형은 자료의 표현 방법, 메모리 크기로 분류됩니다.

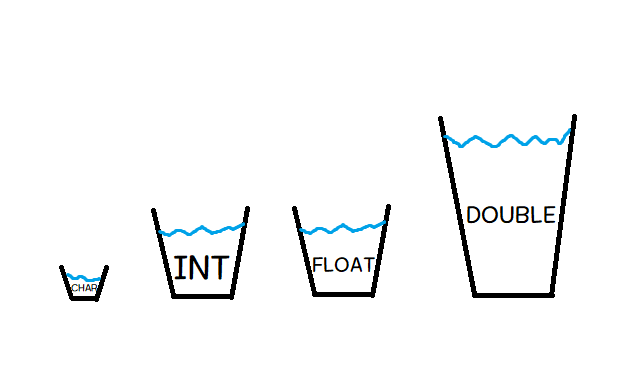


자료형의 기본적인 구분
자료형의 개수는 많지만, 크게 구분하면 다음의 5+1가지로 정리됩니다.
자료를 어떻게 표현하는지, 즉 표현 방법에 따른 분류입니다.
- 정수 자료형 (Integer Type)
ㄴ 1, 2, 3, 4, ... - 부동소수점 자료형 (Floating Point Type)
ㄴ 0.1, 0.2, 0.3, 3.14, ... - 문자 자료형 (Character Type)
ㄴ 'a', 'b', 'c', '!', ... - 문자열 자료형 (String Type)
ㄴ "Hello, World!", "Good Night.", ... - 불리언 자료형 (Boolean Type)
ㄴ true, false - 참조 자료형 (Reference Data Type) -> 포인터, 배열 (나중에!)
부동소수점 자료형과 불리언 자료형, 참조 자료형은 금시초문이실 겁니다.
부동소수점 자료형은 흔히 생각하는 실수 자료형(0.1, 3.14 등등)이고,
불리언 자료형은 True와 False의 두 가지 값 만을 가지는 자료형입니다.
컴퓨터가 0과 1로 된 신호를 통해 동작하니, 불리언 자료형이 가장 컴퓨터공학의 근본적인 자료형이라 할 수 있겠네요.
False가 0, True가 1에 대응됩니다.
참조 자료형은 C언어에서는 포인터, 배열이라 불리는 것들인데요.
C언어의 최종막에 해당하는 개념들이니 지금은 무시하셔도 되겠습니다.
참조 자료형을 무시하면,
수많은 자료형들은 위 다섯 가지 계파의 자료형들을 기반으로 만들어져 있습니다.
그리고 각 계파에서 메모리 크기별로 다양한 자료형들이 파생됩니다.
항공우주 분야의 매우 큰 수치에 높은 정밀도를 요하는 숫자들을 다루는 경우에는 메모리 크기가 커야겠지만,
구구단을 외는데 쓰이는 정도의 간단한 숫자들만 다룰 것이라면 메모리 크기가 작아도 되겠죠.
예를 들어, 정수 자료형의 계파를 골랐다 칩시다.
그러면 C언어에서는 아래와 같이 나뉩니다.
- 2바이트 정수 자료형 short
- 4바이트 정수 자료형 int, long
- 8바이트 정수 자료형 long long
이름이 대부분 직관적이어서 메모리 크기 비교가 쉽고, 다들 2의 거듭제곱(2n) 꼴의 메모리 크기를 가지니
대충 크기가 작을 것 같은 것부터 클 것 같은 것 순서대로 나열한 뒤,
1바이트, 2바이트, 4바이트, 8바이트라 추측해도 다 맞는다는 겁니다.
실제로 short, long, long long 순서대로 2바이트, 4바이트, 8바이트죠?
그래서 겉으로 보이는 것보다는 외우기가 훨씬 쉬울 것입니다.
여러분들의 직관과 곱셈 실력을 믿으세요!
짧다는 놈, 길다는 놈, 길고 길다는 놈 아닙니까.
제곱계산을 할 줄 알면, 틀리기가 더 힘듭니다.
자, 요약하면
참조 자료형을 제외하면 자료형은 정수, 부동소수점(실수), 문자, 문자열, 불리언의 5가지 계파가 있고요.
각 계파의 자료형들은 그 안에서 또 메모리 크기별로 분류되어 있습니다.
상황에 꼭 맞는 메모리만 받기 위해서요.
요즘에야 기가바이트 단위의 메모리가 흔하지만 플로피디스크가 50KB, 하드디스크가 40MB 용량이던 시절에는 메모리를 최대한 아껴써야 했습니다.
1984년 출시된 Apple Computers의 Macintosh PC는 128KB의 메모리를 탑재했죠.
당연하게도, 그 메모리 위에서 운영체제도 돌려야 하고 여러 프로그램을 동시에 실행할 수 있어야 하니 하나의 프로그램이 사용할 수 있는 용량은 훨씬 적었습니다.
그래서 당시의 C언어 표준위원회 여러분들은 메모리 효율과 절약정신을 중시했습니다.
덕분에 여러분들의 암기 효율은 떨어지겠지만요.
그리고 정수 자료형 계파들은 예외적인 사항 하나가 더 있는데요, 별 거 아닙니다.
정수 자료형들은 +/- 부호가 있는 자료형과 없는 자료형을 구분합니다.
부호가 없는 자료형은 음수의 표현을 고려할 필요가 없어 표현 가능한 최댓값이 더 커지죠.
int의 경우 부호가 있는 것은 -21억~+21억의 범위를 갖는데, 부호가 없는 것은 0~42억의 범위를 갖습니다.
덜컥 겁을 먹으실 필요는 없습니다.
왜냐면 외우기 쉽게, 모든 부호가 없는 정수 자료형은 앞에 unsigned라는 수식어가 붙으니까요.
부호가 있는 정수 자료형들만 외운 다음에 그 자료형들의 부호가 없는 버전은 앞에 unsigned를 붙이면 된다고 생각하시면 됩니다.
표현 가능한 최댓값은 음수, 양수 두 갈래가 양수의 한 갈래로 줄었으니 두 배가 되겠죠?
하지만 범위의 크기는 동일하다는 거!

C언어 자료형 표
| char | 문자 자료형 (signed나 unsigned없이 char로만 선언하면 구현 환경에 따라 둘 중 하나로 결정됨. 일반적으론 signed char와 같음.) |
1바이트(8비트) | CHAR_MIN ~ CHAR_MAX |
| signed char | 문자 자료형 | 1바이트(8비트) | SCHAR_MIN ~ SCHAR_MAX [-128, +127] |
| unsigned char | 문자 자료형 | 1바이트(8비트) | 0 ~ UCHAR_MAX [0, 255] |
| short short int signed short signed short int |
정수 자료형 | 2바이트(16비트) | SHRT_MIN ~ SHRT_MAX [-32,768, +32,767] |
| unsigned short unsigned short int |
정수 자료형 | 2바이트(16비트) | 0 ~ USHRT_MAX [0, 65,535] |
| int signed signed int |
정수 자료형 (int는 원래 CPU의 레지스터 크기와 동일한 크기를 갖는 것이 규약이나, 64비트 레지스터가 보편화된 요즘에도 통상적으로 int는 32비트이다.) |
4바이트(32비트) | INT_MIN ~ INT_MAX [−2,147,483,648, +2,147,483,647] (-21억, 21억) |
| unsigned unsigned int |
정수 자료형 | 4바이트(32비트) | 0 ~ UINT_MAX [0, 4,294,967,295] (0, 42억) |
| long long int signed long signed long int |
정수 자료형 | 4바이트(32비트) | LONG_MIN ~ LONG_MAX [−2,147,483,648, +2,147,483,647] (-21억, 21억) |
| unsigned long unsigned long int |
정수 자료형 | 4바이트(32비트) | 0 ~ ULONG_MAX [0, 4,294,967,295] (0, 42억) |
| long long long long int signed long long signed long long int |
정수 자료형 | 8바이트(64비트) | LLONG_MIN ~ LLONG_MAX [−9,223,372,036,854,775,808, +9,223,372,036,854,775,807] (-900경, 900경) |
| unsigned long long unsigned long long int |
정수 자료형 | 8바이트(64비트) | 0 ~ ULLONG_MAX [0, 18,446,744,073,709,551,615] (0, 1800경) |
| float | 부동소수점 자료형 | 4바이트(32비트) | 3.4E+/-38 (7개의 자릿수) |
| double | 부동소수점 자료형 | 8바이트(64비트) | 1.7E+/-308 (15개의 자릿수) |
| long double | 부동소수점 자료형 (구현 환경에 따라 double과 크기가 동일하거나, 더 크다.) |
8바이트(64비트) 또는 16바이트(128비트) |
double 이상의 표현 범위 |
| bool | 불리언 자료형 | 1바이트(8비트) | true, false |
2 4 8
short int,long long long
──────────>
float double long double
4 8 8/16
char 1 bool 1
눈여겨 볼 부분들은 파란색 강조 표시를 했습니다.
왜 이렇게 많나요..!
글을 포스팅하는 입장에서도 되게 오래 표를 작성해야 되서 기분 나쁘네요 ㅡ.ㅡ
이 표를 통째로 외우려고 생각하지 마세요.
다시 한번 정리해드릴 테니, 외우는 게 아니라 100% 맞을 수 밖에 없는 추측을 하시면 됩니다.
- 자료형은 크게 5+1가지의 계파가 있다. { 정수, 부동소수점, 문자, 문자열, 불리언, 참조 }
- 각 계파 안에서 메모리 크기별로 자료형들이 분류된다.
- 그 모든 메모리 크기는 2의 거듭제곱(2n) 꼴이다.
- 정수 자료형은 unsigned와 signed 수식어를 통해 +/- 부호 유무를 나타낸다.
- C언어에서 char은 1바이트 정수 자료형으로도 취급되므로, char 역시 unsigned와 signed가 존재한다.
- 일반적으로 signed는 생략한다.
- unsigned 타입은 음수, 양수 두 갈래로 표현하던 걸 한 갈래로 줄였으므로, 표현 가능한 최댓값이 두 배가 된다. (단, 범위의 크기는 그대로이다.)
전공생들은 첫 중간고사에 이 표를 마주할 일이 있을 수도 있겠죠.
외우는 게 아니라 100% 맞을 수 밖에 없는 추측을 하시라고 말씀은 드렸지만,
솔직히 시험을 보는 입장이 된다면 그런 거 불안해서 못 하고 통째로 외우려 들게 됩니다.
저는 다행히도 좋은 교수님을 만나서, 위 표를 통째로 외우는 불상사는 없었습니다.
그러나, 여러분들이 출제자의 입장이 되어보세요.
문제 몇 개를 날로먹을 수 있는, 아주 탐욕스러운 표 아닙니까.
괜시리 이 표를 하염없이 외우게 될 분들이 불쌍하게 느껴지네요.
사실 이런 거, 그냥 코딩하다보면 안 외우려 해도 자연스럽게 외워집니다...
스타크래프트 게임을 즐기신 분들 중에서, 맵 에디터를 사용해 유즈맵(사용자가 직접 만든 맵)을 만들어 보셨던 분들은, 업그레이드를 최대 255까지 만들 수 있고, 공격력의 최댓값이 65535였던 걸 아실 겁니다.


스타크래프트도 되게 오래된 게임이죠.
255는 unsigned char의 최댓값이고 65535는 unsigned short의 최댓값이네요.
메모리를 절약하려 했던 노력이 돋보입니다.
그러나 여러분들이 실제로 프로그래밍을 할 때에 같은 방식으로 절약하려 하진 마세요.
CPU의 레지스터 크기가 32비트, 64비트, 심지어는 128비트인 시기가 왔잖아요?
CPU의 레지스터 크기는 CPU의 기본 처리 단위이기 때문에, 8비트 데이터를 넣든, 32비트 데이터를 넣든 레지스터 크기대로 처리합니다.
32비트 레지스터를 가진 CPU에 8비트 데이터를 넣어도, 나머지 24비트가 0일 뿐인 32비트 데이터로 처리되니까 사실상 절약이 되지 않습니다.
16비트 데이터를 넣으면, 나머지 16비트가 0일 뿐인 32비트 데이터로 처리하겠죠.
무슨 말인지 아시겠습니까?
8비트나 16비트나 어차피 32비트 시스템에서는 32비트로 처리되니까 절약이 안된다니깐요.
이런 건 있습니다. 유튜브의 이야기인데요.
최근 싸이 유튜브 영상의 조회수가 21억 뷰를 넘어가자 유튜브는 조회수 체계를 21억이 한계인 32비트 정수 체계(int)에서 900경이 한계인 64비트 정수 체계(long long)으로 바꾸었습니다.

이처럼 절약의 반대로, 확장이 필요한 경우는 여러분들이 실제 코딩하면서도 많이 마주칠 수 있을 겁니다.
그 부분의 이야기가 다음 글에서 다룰 내용이 되겠죠.
기대하시기 바랍니다.

자료형별 메모리 크기와 표현 가능한 최솟값, 최댓값을 출력해보기
위의 표에서 각 자료형별 메모리 크기와 표현 가능한 범위를 알아봤을 것입니다.
실제로 프로그래밍을 통해 직접 값들을 출력해보고 우리가 알아본 값과 일치하는지 확인하면서,
더 내용을 기억에 새깁시다.

오늘 소스의 이름은 이번 글의 제목인 "3. 다양한 자료형.c"입니다.
|
#include <stdio.h>
int main()
{
printf("int의 메모리 크기 : %zu\n", sizeof(int));
return 0;
}
|
cs |
간단하게, 자료형의 대표주자격인 int의 메모리 크기만을 찍어보았습니다.
sizeof(...) 연산자는 ...에 해당하는 자료형의 메모리 크기를 알아내는 연산자입니다.
sizeof(int)는 int의 메모리 크기를 알아내겠다는 뜻이죠.
%zu는 예전의 %d, %lf, %c와 비슷한 역할을 하는 친구인데요.
뒤의 sizeof(int)와 연결된다고 생각하시면 됩니다.
이것은 서식 한정자라고 해서, printf 함수 자체를 깊이 다룰 때에 한 번에 소개해드릴 예정입니다.

실행하면 위와 같은 결과가 나옵니다.
4라는 숫자가 출력되었는데, 4바이트라는 말이겠죠?
4바이트라면 우리가 앞선 표에서 본 값과 일치합니다.
그럼 다른 자료형의 메모리 크기도 알아봅시다.
|
#include <stdio.h>
#include <stdbool.h>
int main()
{
printf("char의 메모리 크기 : %zu\n", sizeof(char));
printf("short의 메모리 크기 : %zu\n", sizeof(short));
printf("int의 메모리 크기 : %zu\n", sizeof(int));
printf("long의 메모리 크기 : %zu\n", sizeof(long));
printf("long long의 메모리 크기 : %zu\n", sizeof(long long));
printf("float의 메모리 크기 : %zu\n", sizeof(float));
printf("double의 메모리 크기 : %zu\n", sizeof(double));
printf("long double의 메모리 크기 : %zu\n", sizeof(long double));
printf("bool의 메모리 크기 : %zu\n", sizeof(bool));
return 0;
}
|
cs |
bool의 경우에는 C99 표준으로 매우 오래됐음에도 불구하고,
<stdbool.h>를 번거롭게 포함시켜야만 이용할 수 있습니다.
만약 bool에 빨간 줄이 쳐져있다면, 두 번째 줄의 #include <stdbool.h>를 적어주세요.

Visual Studio의 경우에는 long double을 8바이트로 구현했군요! 아쉬울 따름입니다.
각 자료형들의 메모리 크기를 살펴보니 역시 우리가 공부했던 값들과 다르지 않습니다.
이제 각 자료형별 표현 가능한 최솟값과 최댓값도 알아볼까요?
|
#include <stdio.h>
#include <stdbool.h>
#include <limits.h>
int main()
{
printf("char의 메모리 크기 : %zu\n", sizeof(char));
printf("short의 메모리 크기 : %zu\n", sizeof(short));
printf("int의 메모리 크기 : %zu\n", sizeof(int));
printf("long의 메모리 크기 : %zu\n", sizeof(long));
printf("long long의 메모리 크기 : %zu\n", sizeof(long long));
printf("float의 메모리 크기 : %zu\n", sizeof(float));
printf("double의 메모리 크기 : %zu\n", sizeof(double));
printf("long double의 메모리 크기 : %zu\n", sizeof(long double));
printf("bool의 메모리 크기 : %zu\n", sizeof(bool));
printf("int의 최솟값 : %d\n", INT_MIN);
printf("int의 최댓값 : %d\n", INT_MAX);
return 0;
}
|
cs |
역시 먼저 int에 대해서만 알아보았습니다.
INT_MIN과 INT_MAX는 이름에서도 알 수 있듯, int의 최솟값과 최댓값을 저장한 상수로,
<limits.h>에 선언되어 있습니다.
3번째 줄의 #include <limits.h>를 빠뜨리지 말고 적어주세요.
INT_MIN과 INT_MAX에 빨간 줄이 쳐져있다면, 빠뜨린 겁니다.

역시 표에서 알아본 값과 동일하죠?
나머지도 확인해보는데, 코드가 쓸 데 없이 길어지는 건 싫으니
char과 unsigned char, unsigned int만 추가해봅시다.
|
#include <stdio.h>
#include <stdbool.h>
#include <limits.h>
int main()
{
printf("char의 메모리 크기 : %zu\n", sizeof(char));
printf("short의 메모리 크기 : %zu\n", sizeof(short));
printf("int의 메모리 크기 : %zu\n", sizeof(int));
printf("long의 메모리 크기 : %zu\n", sizeof(long));
printf("long long의 메모리 크기 : %zu\n", sizeof(long long));
printf("float의 메모리 크기 : %zu\n", sizeof(float));
printf("double의 메모리 크기 : %zu\n", sizeof(double));
printf("long double의 메모리 크기 : %zu\n", sizeof(long double));
printf("bool의 메모리 크기 : %zu\n", sizeof(bool));
printf("char의 최솟값 : %d\n", CHAR_MIN);
printf("char의 최댓값 : %d\n", CHAR_MAX);
printf("unsigned char의 최댓값 : %d\n", UCHAR_MAX);
printf("int의 최솟값 : %d\n", INT_MIN);
printf("int의 최댓값 : %d\n", INT_MAX);
printf("unsigned int의 최댓값 : %u\n", UINT_MAX);
return 0;
}
|
cs |
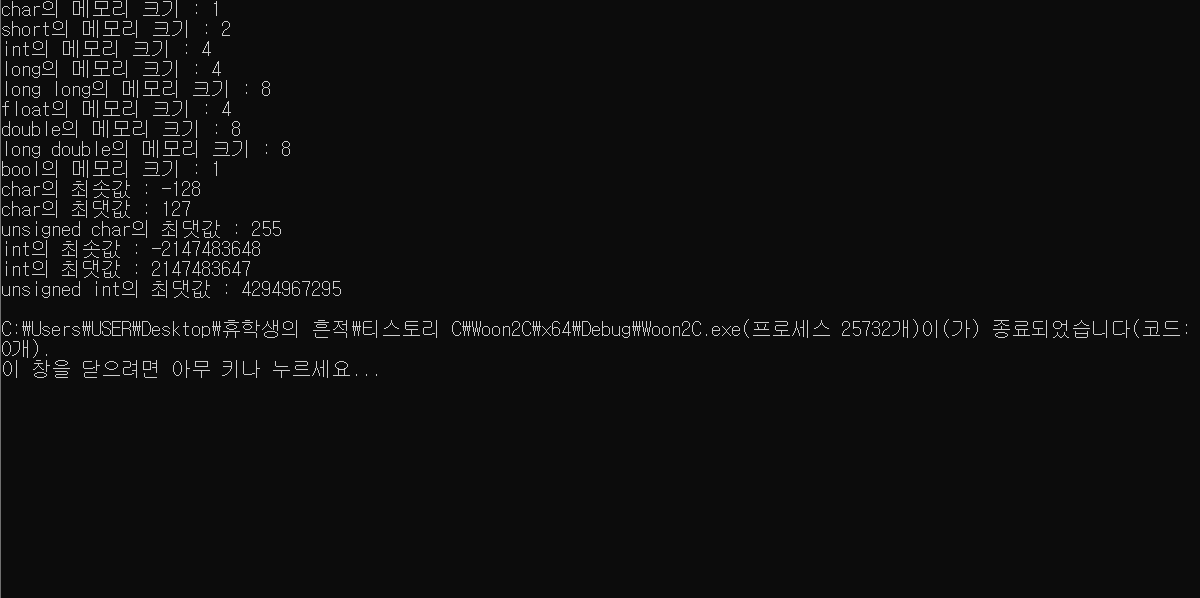
실행 결과입니다.
한 번 쯤은 직접 표와 대조하면서 확인해보세요.
사실 오늘 코드로 쓴 것들은 모르는 개념들 천지라 아예 눈에 안 들어오실 수도 있을 겁니다.
그래도 일단 꼭 따라 써보시기 바랍니다.
서식 한정자나, sizeof 연산자나 실제로도 빈번히 쓰이는 것들이거든요.
오늘도 무거운 한 발짝을 옮긴 여러분들께 박수를 올립니다.
점점 익숙해지셔서 C언어를 공부하는 여정이 가벼운 발걸음이 되셨으면 좋겠습니다.
다양한 자료형 표는 아래 두 링크를 참고하여 작성했습니다..
https://en.wikipedia.org/wiki/C_data_types
C data types - Wikipedia
From Wikipedia, the free encyclopedia Jump to navigation Jump to search Data types supported by the C programming language In the C programming language, data types constitute the semantics and characteristics of storage of data elements. They are expresse
en.wikipedia.org
https://docs.microsoft.com/ko-kr/cpp/cpp/data-type-ranges?view=msvc-170
데이터 형식 범위
자세한 정보: 데이터 형식 범위
docs.microsoft.com

'C | C++ > C' 카테고리의 다른 글
| [C] 6. printf를 좀 더 잘 써봅시다. <필드폭 및 소수점 조정, 이스케이프 문자> (1) | 2022.07.05 |
|---|---|
| [C] 5. 입출력은 프로그램의 근본입니다. <printf, scanf> (0) | 2022.07.05 |
| [C] 4. 변수의 최댓값을 넘기면 무슨 일이 일어날까요? <오버플로우, 언더플로우, 랩 어라운드> (0) | 2022.07.03 |
| [C] 2. 올바른 이름을 적읍시다. <변수의 이름 규칙> (0) | 2022.06.25 |
| [C] 1. 처음은 변수를 만들어보는 것으로 시작합시다. <변수 선언, 초기화> (0) | 2022.06.10 |