

힙 메모리 단편화
힙 단편화( heap fragmentation ), 메모리 단편화( memory fragmentation )이라 부르는 이 현상은
객체를 자주 동적할당할 때 발생한다.
메모리들이 직렬화되어 전부 붙어있으면 좋겠지만, 힙 메모리에서는 메모리들이 붙어있다고 장담할 수 없다.
할당되는 메모리 조각들은 서로 거리가 있는 편이다.
어쩌다가 연속된 메모리들이 있어도 중간에 메모리를 삭제해버리면 그 사이에 원래 있던 메모리 만큼의 틈이 발생하게 된다.

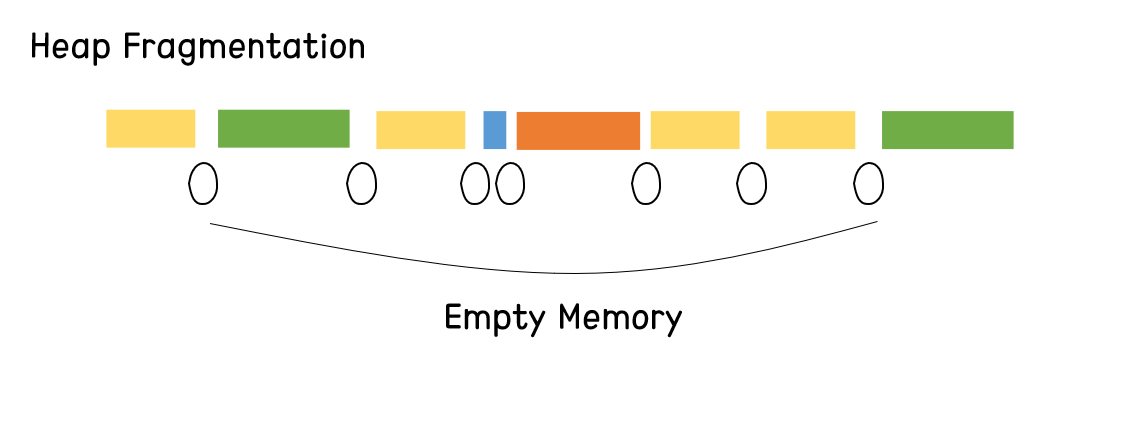

힙 메모리 단편화로 인해 빈 메모리가 자주 발생해버리면, 실제 메모리 크기에는 여유가 있지만 특정한 크기의 객체를 할당할 수 없는 일이 발생한다.
- 빈 메모리 총합은 10000 byte 지만 모든 빈 메모리가 1000 byte 이하일 경우, 2000 byte 크기의 객체는 단 한 개도 할당할 수 없다. 100 byte 크기의 객체는 100개를 할당할 수 있는데 말이다.
실제로 프로그램이 들고있는 메모리는 얼마 안되더라도 게임과 같이 빈번히 동적할당이 이루어지는 프로그램에선 겨우 10분만에도 힙 메모리가 난장판이 될 수 있다.
메모리 풀, 오브젝트 풀을 이용한 메모리 최적화
객체를 동적할당할 때에, 배열로 한꺼번에 할당하면 할당받은 메모리 내에서 요소들이 연속적으로 배치되어 있도록 할 수 있다.
메모리 단편화가 발생하는 건, 메모리 조각을 여러 번 할당하고 제거하기 때문이다.
배열을 위한 큰 메모리 조각을 할당받고 그 안에서 메모리를 잘게 나누어 사용하면 할당된 메모리 조각은 한 개이지만 여러 메모리 조각을 할당한 효과를 볼 수 있다.
힙은 자신이 할당할 메모리 조각의 크기만 알지, 그게 어떻게 쓰일지는 모른다. 큰 메모리 하나로 사용하든, 작은 메모리의 배열로 사용하든, 사용자의 마음대로 할 수 있다. ( 사실 배열을 할당할 경우 배열을 할당한다는 것을 알긴 안다. 할당되는 메모리에 추가적으로 배열의 크기를 써놓는다. 따라서 delete[] 는 배열의 크기를 지정하지 않아도 배열의 크기만큼 메모리를 지울 수 있다. )
작은 메모리 조각을 힙의 이곳 저곳에서 여러 번 할당받으면 앞서 언급한 힙 메모리 단편화가 발생하기 때문에 큰 메모리 조각에 배열을 할당받아 단편화를 막는다.

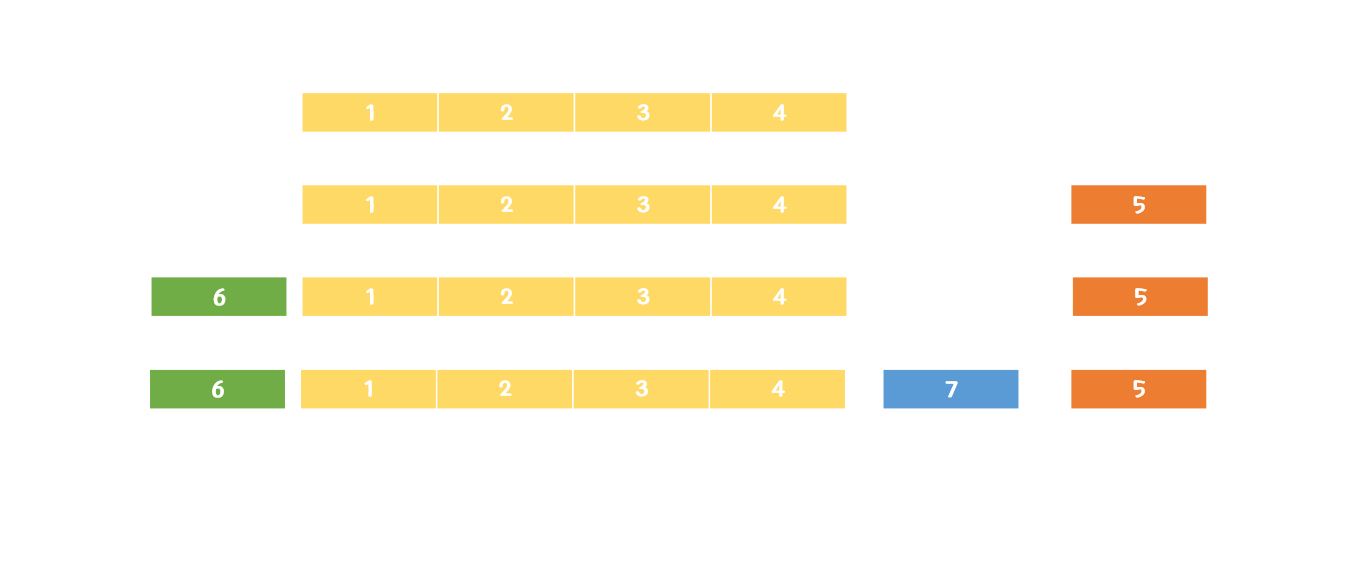
메모리 풀( memory pool ), 오브젝트 풀( object pool ) 개념이 여기서 등장한다.
객체를 따로따로 생성한다는 것은 객체가 필요한 시점이 다르다는 말이다.
처음부터 10개의 객체가 필요할 것을 아는 프로그래머는 그 객체 10개짜리의 배열을 선언할 것이다.
메모리 풀과 오브젝트 풀은 지금 당장 필요한 메모리나 객체만 할당하는 게 아니라 이후에 객체가 필요해질 것을 예측하여 메모리나 객체를 미리 한꺼번에 할당해놓는다.
그렇게 모아진 집합체를 풀( pool )이라고 부르며, 실제로 객체가 필요해질 때는 새로이 객체를 생성하는 게 아니라 풀에서 메모리나 객체를 꺼내와서 사용한 뒤, 사용이 끝나면 반납한다.
풀이 도서관이라면, 이용할 메모리나 객체가 책이라고 할 수 있겠다.
보통 풀은 비슷한 크기의 객체끼리 모아놓아야 메모리 크기가 딱딱 떨어져서 최대 효율을 가진다.
그래서 보통 풀을 구현할 때는 크기별로 따로 구현한다.

메모리 풀과 오브젝트 풀 중에서는 메모리 풀이 상위 개념이라 할 수 있다.
할당된 메모리 자체로는 작업을 할 수 없다. 그 메모리에 객체라는, 의미있는 데이터를 써놓아야 활용할 수 있다.
이것을 객체 생성이라 한다.
오브젝트 풀은 이미 "생성되어 있는 객체"를 반환하고, 메모리 풀은 "생성에 필요한 메모리"를 반환하도록 만들어진다.
자유도는 메모리 풀이 더 높지만, 구현이 간편한 것은 오브젝트 풀이다. 메모리 확보와 객체 생성을 분리할 필요가 없으니까. 이것을 분리하게 되면 코드가 복잡해진다.
풀을 이용함으로써 메모리 단편화 걱정을 줄이고 프로그램이 이용할 수 있는 메모리를 최대한 이용할 수 있다.
메모리 풀, 오브젝트 풀의 부수효과
메모리 풀, 오브젝트 풀을 이용함으로써 성능 향상의 효과도 누릴 수 있다.
일반적으로 동적할당은 성능 저하의 아이콘이다.
c++ 기준에서, new 의 동적할당은 다음과 같은 일을 한다.
- 메모리 할당( c의 malloc과 같다. )
- 생성자 호출
- 가상 함수 목록 설정( Virtual Method Table Setting )
여기서 풀을 이용함으로써 확실하게 줄어드는 것은 메모리 할당이다. ( 풀에서 메모리를 할당받을 때 객체 타입으로 operator new를 호출하면 세 가지를 다 하고, 필요한 바이트들만 할당받으면 메모리 할당만 하는 게 된다. )
메모리 할당은 시스템콜로 메모리를 요청한다.
사용자의 운영체제와 상호작용하여 유효한 메모리를 할당받는데, 이 과정에서 소요되는 cpu 비용이 매우 크다.
하지만 한 번의 시스템콜을 통해서 메모리를 풀에 미리 할당받아 놓으면, 풀에서 메모리를 꺼낼 때에는 시스템콜이 발생하지 않으므로 cpu 가 훨씬 적은 동작을 해 성능이 향상된다.

간단한 오브젝트 풀 구현
|
#include <iostream>
#include <list>
using namespace std;
template <typename Ty, size_t pool_size>
class Pool
{
public:
Ty* allocate()
{
cout << "할당\n";
auto ret = available_list.front();
available_list.pop_front();
return ret;
}
void deallocate( Ty* exhausted )
{
cout << "반납\n";
available_list.push_back( exhausted );
}
Pool() : objects{ new Ty[ pool_size ] }
{
for ( size_t i = 0; i < pool_size; ++i )
{
available_list.push_back( &objects[ i ] );
}
}
~Pool() { delete[] objects; }
Pool( const Pool& other ) = delete;
Pool& operator=( const Pool& ) = delete;
private:
Ty* objects;
list<Ty*> available_list;
};
class Object
{
public:
Object()
{
cout << "오브젝트 생성자!\n";
}
~Object()
{
cout << "오브젝트 소멸자!\n";
}
int woon2[ 100 ];
int world[ 100 ];
};
int main()
{
Pool< Object, 10 > s; // 오브젝트 10개짜리 풀
auto obj = s.allocate();
for ( int i = 0; i < 100; i += 10 )
{
obj->woon2[ i ] = i;
obj->world[ i ] = i;
cout << obj->woon2[ i ] << ", " << obj->world[ i ] << endl;
}
auto obj2 = s.allocate();
auto obj3 = s.allocate();
s.deallocate( obj );
s.deallocate( obj2 );
s.deallocate( obj3 );
}
|
cs |

코드는 그대로 복사 붙여넣기만 하면 동작해 테스트 해볼 수 있다.
풀은 생성시에 객체들을 한번에 생성하고 소멸시에 객체들을 한번에 소멸시킨다.
풀이 요청에 의해서 객체를 할당할 때에는 이용 가능한 객체의 주소를 반환한다.
객체 자체를 반환하는 것은 불가능하다.
한 지역은 자신의 지역에 있는 메모리만 이용할 수 있다.
따라서 다른 지역에 있는 메모리를 얻어올 때는, 자신의 지역에 메모리를 마련해놓고 복사한다.
컴퓨터 내의 메모리는 절대로 이동하지 않는다.
따라서 다른 지역에 할당된 메모리를 참조하려면 메모리를 받는 게 아니라 메모리의 주소를 받아야 한다.
그 주소를 역참조하면 원격으로 메모리를 조작할 수 있다.
new나 malloc이 객체가 아니라 객체의 포인터를 돌려주는 것도 그러한 이유이다.
후에 객체 주소가 다시 반납되어 올 때까지 동일한 객체는 재할당이 불가능하다.
( A라는 책을 어떤 사람이 빌려간 채 반납하지 않았다면, A는 대출이 불가능하다. )
c++의 new와 delete처럼, 할당과 반납을 따로 짝지어줘야 한다는 불편함이 있다.
스마트포인터처럼 RAII 를 활용하여 반납을 자동화할 수도 있겠다.
또한 무조건 오브젝트 타입의 기본 생성자를 호출하게 되어있어 기본 생성자가 정의되지 않은 오브젝트를 담을 수 없고, 생성자를 나중에 호출해야 하는 경우 생성자가 두 번 불리게 된다.
이렇게 소소한 문제들이 있지만 작은 프로젝트에서 이용하기에 간단하면서 범용성이 높다.
현재 개발중인 메모리 풀
메모리 풀은 정적인 크기를 갖느냐 동적인 크기를 갖느냐로 다시 한 번 나뉜다.
정적 메모리 풀의 경우 프로그램 실행 내내 일정한 크기의 메모리를 들고 있어 할당과 제거가 단 한 번밖에 일어나지 않는다.
하지만 실제로 사용하고 있는 객체가 거의 없어도 항상 최대 용량만큼의 메모리를 들고있어야 하기 때문에 메모리 낭비가 발생할 수 있다.
동적 메모리 풀은 메모리를 블록 단위로 할당받아 가변적인 개수의 블록을 들고있을 수 있다.
하지만 구현 난이도가 어렵고 추가적인 메모리 관리 동작이 성능을 저하시킨다는 단점이 있다.
현재 만들고 있는 것은 동적 메모리 풀로, 할당 시에 std::list 를 이용한 가용 블록 목록으로 할당 시에 가용 블록 목록의 가장 앞에 있는 블록에서 메모리를 꺼내온다.
삭제 시에는 메모리 블록을 상수 시간 내에 찾기 위해 std::unordered_set 을 활용한 해시테이블로 블록을 검색한다.
memory_pool 클래스를 CRTP 패턴을 활용한 상속에 쓰일 인터페이스 클래스로 구축했으며
메모리풀을 적용할 클래스는 이 클래스를 상속함으로써 클래스 단위로 메모리 풀이 구현된다.
memory_pool 클래스는 내부 클래스로 memory_block 을 가지고 있다.
memory_pool 이 memory_block 을 관리하고, memory_block 이 실제 메모리를 관리한다.
|
// memorypool.h
#ifndef _memorypool #define _memorypool
#include <unordered_set>
#include <list>
#include "TMP.h"
#include <iostream>
#include <algorithm>
#ifdef max // disable c macro
#undef max
#endif
// Ty : object type, unit : number of objects to allocate at once
template < typename Ty, size_t unit >
class memory_pool INTERFACE
{
public:
using byte = char;
using byte_pointer = byte*;
using byte_pointer_address = byte**;
using object = Ty;
static constexpr int null() { return 0; }
static void* operator new( size_t alloc_memory_length )
{
std::cout << "operator new!\n";
create_block_if_thereis_no_available_block();
return allocate_memory_in_available_block( alloc_memory_length );
}
static void operator delete( void* exhausted_memory )
{
std::cout << "operator delete!\n";
for ( auto block : memory_blocks )
{
if ( block->is_in( exhausted_memory ) )
{
if ( block->full() )
{
available_blocks.push_back( block );
}
block->deallocate( exhausted_memory );
if ( block->empty() )
{
delete block;
memory_blocks.erase( block );
available_blocks.erase(
std::find( available_blocks.begin(), available_blocks.end(), block )
);
}
return;
}
}
}
private:
class memory_block
{
public:
void* allocate( size_t alloc_memory_length ) noexcept
{
std::cout << "memory_block::allocate!\n";
// get free object and move free_pointer to next.
byte_pointer available_memory = free_pointer;
// reinterpret_cast for moving free_pointer to next
// dereferencing gets exact size of the pointer, not size of a byte.
free_pointer = *reinterpret_cast< byte_pointer_address >( free_pointer );
++obj_cnt;
return available_memory;
}
void deallocate( void* exhausted_memory ) noexcept
{
std::cout << "memory_block::deallocate!\n";
// to-delete object becomes a free object,
// so write current free object's address on to-delete object's head.
*reinterpret_cast< byte_pointer_address >( exhausted_memory ) = free_pointer;
free_pointer = static_cast< byte_pointer >( exhausted_memory );
--obj_cnt;
}
memory_block() : mem_size{ sizeof( object ) * unit + sizeof( void* ) },
free_pointer{ nullptr }, block_address{ nullptr }, obj_cnt{ 0 }
{
std::cout << "memory_block::memory_block!\n";
allocate_block();
write_empty_memory_sequence();
}
~memory_block()
{
std::cout << "memory_block::~memory_block!\n";
delete[] block_address;
}
const bool full() const noexcept NOASSIGNMENT
{
std::cout << "memory_block::full!\n";
// the last object points null.
return nullptr == free_pointer;
}
const bool empty() const noexcept NOASSIGNMENT
{
std::cout << "memory_blockk::empty!\n";
return 0 == obj_cnt;
}
const bool operator<( const memory_block& rhs ) const noexcept NOASSIGNMENT
{
return block_address < rhs.block_address;
}
const bool operator<( memory_block&& rhs ) const noexcept NOASSIGNMENT
{
return block_address < rhs.block_address;
}
const bool operator==( const memory_block& rhs ) const noexcept NOASSIGNMENT
{
return block_address == rhs.block_address;
}
HELPER const bool is_in( void* finding_memory ) const noexcept
{
std::cout << "memory_block::is_in!\n";
return subtract_no_underflow( reinterpret_cast< unsigned long long >(finding_memory), mem_size )
< reinterpret_cast< unsigned long long >(block_address)
&& block_address <= finding_memory;
}
private:
const unsigned long long subtract_no_underflow( const unsigned long long lhs, const unsigned long long rhs ) const noexcept
{
return std::max( lhs - rhs, 0ull );
}
HELPER void allocate_block()
{
std::cout << "memory_block::allocate_block!\n";
// additionally allocate size of a pointer for safe object address writing.
free_pointer = new byte[ mem_size ];
block_address = free_pointer;
}
HELPER void write_empty_memory_sequence() noexcept
{
std::cout << "memory_block::write_empty_memory_sequence!\n";
// reinterpret_cast for writing next object's address on empty objects' head
// dereferencing gets exact size of the pointer, not size of a byte.
byte_pointer_address cur = reinterpret_cast<byte_pointer_address>( free_pointer );
byte_pointer next = free_pointer;
// unit - 1 is the last index,
// at unit - 2 next points the last.
for ( int i = 0; unit - 1 > i; ++i )
{
next += sizeof( object );
// write next object's address on empty current object's head.
*cur = next;
cur = reinterpret_cast<byte_pointer_address>( next );
}
// the last object points null.
*cur = nullptr;
}
byte_pointer free_pointer;
byte_pointer block_address;
size_t mem_size;
size_t obj_cnt;
};
HELPER static void create_block_if_thereis_no_available_block()
{
std::cout << "create_block_if_thereis_no_available_block!\n";
if ( available_blocks.empty() )
{
auto block = new memory_block;
memory_blocks.insert( block );
available_blocks.push_back( block );
}
}
HELPER static auto allocate_memory_in_available_block( size_t alloc_memory_length )
{
std::cout << "allocate_memory_in_available_block!\n";
auto block{ available_blocks.front() };
auto ret{ block->allocate( alloc_memory_length ) };
if ( block->full() )
{
available_blocks.pop_front();
}
return ret;
}
static std::unordered_set< memory_block* > memory_blocks;
static std::list< memory_block* > available_blocks;
protected:
memory_pool() {} // only created by derived class
};
template< typename Ty, size_t unit >
std::unordered_set<typename memory_pool<Ty, unit>::memory_block*> memory_pool<Ty, unit>::memory_blocks;
template< typename Ty, size_t unit >
std::list< typename memory_pool<Ty, unit>::memory_block* > memory_pool<Ty, unit>::available_blocks;
class TestPool : public memory_pool<TestPool, 4>
{
public:
int a[ 100 ];
};
#endif
|
cs |
- 함수 호출 계층
|
int main()
{
TestPool* a1 = new TestPool;
TestPool* a2 = new TestPool;
TestPool* a3 = new TestPool;
TestPool* a4 = new TestPool;
TestPool* a5 = new TestPool;
TestPool* a6 = new TestPool;
TestPool* a7 = new TestPool;
TestPool* a8 = new TestPool;
TestPool* a9 = new TestPool;
TestPool* a10 = new TestPool;
TestPool* a11 = new TestPool;
TestPool* a12 = new TestPool;
TestPool* a13 = new TestPool;
TestPool* a14 = new TestPool;
TestPool* a15 = new TestPool;
TestPool* a16 = new TestPool;
TestPool* a17 = new TestPool;
TestPool* a18 = new TestPool;
TestPool* a19 = new TestPool;
TestPool* a20 = new TestPool;
TestPool* a21 = new TestPool;
TestPool* a22 = new TestPool;
TestPool* a23 = new TestPool;
TestPool* a24 = new TestPool;
TestPool* a25 = new TestPool;
TestPool* a26 = new TestPool;
TestPool* a27 = new TestPool;
TestPool* a28 = new TestPool;
TestPool* a29 = new TestPool;
TestPool* a30 = new TestPool;
delete a1;
delete a2;
delete a3;
delete a4;
delete a5;
delete a6;
delete a7;
delete a8;
delete a9;
delete a10;
delete a11;
delete a12;
delete a13;
delete a14;
delete a15;
delete a16;
delete a17;
delete a18;
delete a19;
delete a20;
delete a21;
delete a22;
delete a23;
delete a24;
delete a25;
delete a26;
delete a27;
delete a28;
delete a29;
delete a30;
}
|
cs |
위와 같은 무식한 코드에 대해
개선점
- unordered_set 을 이용하면 상수 시간 내에 검색이 될 줄 알았으나 is_in 이 블록 인덱스만큼 호출되고 있다.
- 정정 : 아니었다. 생각해보니 테스트하느라 블록 단위를 4로 만들었으니 30개를 만들었을 때 총 8개의 블록 중에서 찾는 블록을 3~2번의 검색만으로 찾는 것은 훌륭한 것이었다.
- STL의 자료구조를 이용하는 것이 시간을 잡아먹는다.
reinterpret_cast 를 적절히 활용해 메모리 쓰기 만으로 자료구조 없이 자료구조의 효과를 낼 수 있는 방법을 연구해본다. - 한 개의 블록을 항상 미리 할당해 둘 필요가 있다.
요청이 들어오고 나서야 할당을 하면, 한 개의 객체를 할당하는데 한 블록을 할당하는 일도 발생하여 오히려 시간이 더 걸릴 수 있다. - operator delete 의 동작을 서로 다른 함수들로 분리해내어 operator new 처럼 추상화 수준을 높인다.
- 블록의 멤버 초기화 리스트에서 블록 할당이 일어나도록 한다. 지금은 초기화가 아니라 대입이 일어나고 있다.
- substract_no_overflow 는 템플릿으로 일반화하여 TMP.h 에 둘 수도 있을법하다.
- new[]와 delete[]도 정의해준다.
- 메모리 할당 옵션이 unit 수만큼 일정하게 할당하는 것밖에 없으므로, 함수 객체를 통해 여러가지 옵션을 준비한다.
- 간격, 들여쓰기, 키워드 조정을 아직 하지 않았다. 가독성을 늘리고 불필요한 캐스팅을 줄일 필요가 있다.
'Project > Win32API로 던그리드 모작' 카테고리의 다른 글
| git repository 생성 (0) | 2021.09.17 |
|---|---|
| 현재 적용할 메모리 풀 (0) | 2021.09.15 |
| 게임 저장 구현 - 구조체를 파일로 저장하기 (0) | 2021.08.24 |
| 데이터베이스 구현 (0) | 2021.08.23 |
| std::iostream 으로 std::tuple 입출력하기 (0) | 2021.08.23 |